Photo by Rock’n Roll Monkey on Unsplash
Ever had the idea of this amazing data science project, you look up the data you’ll need online but sadly it’s nowhere to be found? Unfortunately, not every dataset you’ll ever need is online. So, what should you do? Abandon your idea and go back to kaggle? No! A real data scientist should be able to collect his own DATA!
What’s Web Scraping and why learn it?
The web is the single biggest resource for data, it’s a literal archive for human knowledge at least for the last 20 years. Web Scraping is the art of extracting that data off the web, as a Data Scientist It is such a handy tool and opens so many doors to cool projects.
Note that some websites prohibit scraping and might ban your IP address if you scrape too frequently or maliciously.
How do we scrape?
There are two approaches when it comes to web scraping.
Request based scraping: With this approach we will be sending a request to the website’s server which will return the HTML of the page which is the same content that you find when you click “View page source” on google chrome, you can try that out right now by pressing ctrl+u .Then we will typically use a library to parse the HTML and extract the data that we want. This approach is simple, lightweight and very fast, however it’s not perfect and there’s one drawback that might put you off using it, in fact most modern websites nowadays use JavaScript to render their content, IE: you don’t see the content of the page until after the JavaScript executes which the request method can’t handle.
Browser based scraping: To execute JavaScript we need a fully-fledged browser, this is what this method is about, we will simulate a browser, navigate to the page we want, wait for JavaScript to execute and we can even interact with the page by clicking buttons, filling forms… Then just look at the HTML state and extract the data. This approach is very flexible, you can pretty much scrape any website you want, however it’s much slower and resource intensive than just sending a request.
Scrape anything with selenium:
Selenium is widely used library for web automation, but you can actually use it for scraping too! Basically any task that a human can manually do, you’ll be able to simulate it with selenium, you can create a bot that will perform certain action when something happens, or you can make selenium browse web pages and scrape data for you which is what we’ll be doing in this article.
To parse the HTML we will be using beautiful soup.
For further reading here are documentation links for selenium and beautiful soup
Demo: Scraping Indeed Jobs
Let’s get some practice, the goal of this demo is to scrape jobs from indeed given a search query and save them in csv file.
More precisely we are interested in:
- Job title
- Location of the job
- Company that posted the offer
- Job description
- When the job was posted
Here a link to a sample job page and here’s the project code
First let’s import the required libraries:
from bs4 import BeautifulSoup
from webdriver_manager.chrome import ChromeDriverManager
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")- Beautiful Soup is for interacting with HTML
- Pandas to export to csv
- The web driver is the actual browser, we will be using chrome and configuring it to run on headless mode which means it will run in the background and we won’t be able to see a browser going through the job pages, this is optional if you want to see the browser you can remove it!
The first thing to do is to get the actual job pages, lucky indeed has a search function, all you have to do is to navigate to :
“https://ma.indeed.com/jobs?q=data+scientist&start=10”
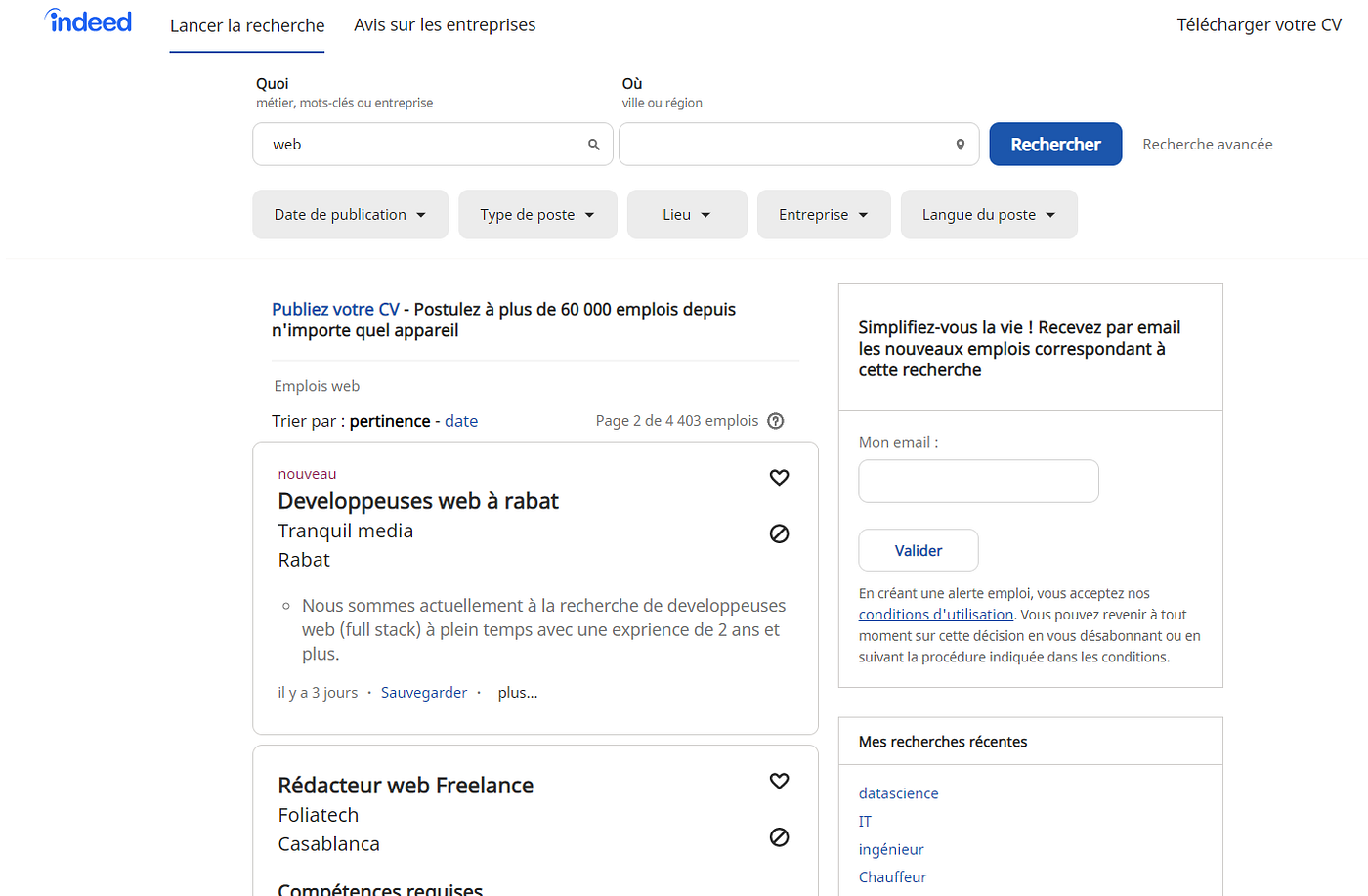
You’ll get the second page of jobs related to data science, so you can specify the search query changing the q argument and the page number changing the start argument. Note that I’m using the Moroccan portal of Indeed, but this will work for any country.
We will be implementing two functions one is a helper function to navigate to a URL extracting the HTML and turning it to Beautiful Soup object that we can interact with and another to extracts links to the job pages:
def toSoup(url):
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
return soupdef getPageUrls(query,number):
url="[https://ma.indeed.com/emplois?q=](https://ma.indeed.com/emplois?q=)"+str(query)+"&start="+str(((number-1)\*10))
soup=toSoup(url)
maxPages=soup.find("div",{"id":"searchCountPages"}).text.strip().split(" ")[3]
return maxPages,[appendIndeedUrl(a["href"]) for a in soup.findAll("a",{"class":"jobtitle turnstileLink"})]Now that we have the URLs let’s implement some functions to extract what we want out of the job page:
def paragraphArrayToSingleString(paragraphs):
string=""
for paragraph in paragraphs:
string=string+"\\n"+paragraph.text.strip()
return stringdef appendIndeedUrl(url):
return "[https://ma.indeed.com](https://ma.indeed.com)"+str(url)def processPage(url):
soup=toSoup(url)
title=soup.find("h1",{"class":"icl-u-xs-mb--xs icl-u-xs-mt--none jobsearch-JobInfoHeader-title"}).text.strip()
CompanyAndLocation=soup.find("div",{"class":"jobsearch-InlineCompanyRating icl-u-xs-mt--xs jobsearch-DesktopStickyContainer-companyrating"})
length=len(CompanyAndLocation)
if length==3:
company=CompanyAndLocation.findAll("div")[0].text.strip()
location=CompanyAndLocation.findAll("div")[2].text.strip()
else:
company="NAN"
location=CompanyAndLocation.findAll("div")[0].text.strip()
date=soup.find("div",{"class":"jobsearch-JobMetadataFooter"}).text.split("-")[1].strip()
description=paragraphArrayToSingleString(soup.find("div",{"id":"jobDescriptionText"}).findAll())
return {"title":title,"company":company,"location":location,"date":date,"description":description}def getMaxPages(query):
url="[https://ma.indeed.com/emplois?q=](https://ma.indeed.com/emplois?q=)"+str(query)Here we are using HTML attributes such as “class” or “id” to locate information we want, you can figure out how to select the data you need by inspecting the page
Here’s an example for the title property:
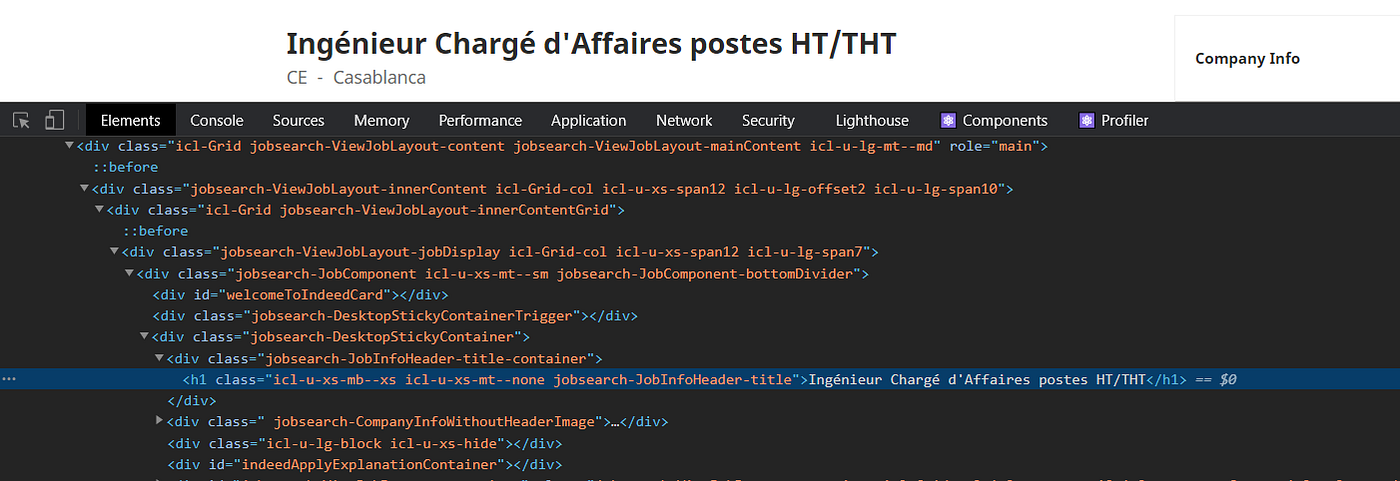
We can see that the title is an “h1” that we can select using its class
Finally let’s implement a function to run get all the jobs and save them in csv file.
Note that we are getting the max pages number so that the crawler stops when we have reached the final page.
def getJobsForQuery(query):
data=[]
maxPages=999
for number in range(maxPages):
maxPages,urls=getPageUrls(query,number+1)
for url in urls:
try:
page=processPage(url)
data.append(page)
except:
pass
print("finished Page number: "+str(number+1))
#Save the data to a csv file
pd.DataFrame(data).to_csv("jobs_"+query+".csv")Now let’s scrape Data Science Jobs:
driver = webdriver.Chrome(ChromeDriverManager().install(),options=chrome_options)
getJobsForQuery("data scientist")Here’s the result:
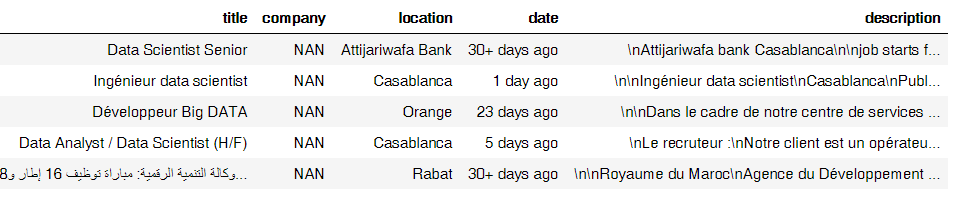 A Sample of scraped jobs
A Sample of scraped jobs
Conclusion
In this article we learned about the web scraping, why it’s important for every aspiring data scientist and the different approaches to do so, and we’ve applied that to scrape jobs from Indeed.
if you managed to get here Congratulations. Thanks for reading, I hope you’ve enjoyed the article. For personal contact or discussion, feel free to reach out to me on LinkedIn.